Institute for Biomedicine - Health Data Science
Health Data Science
"It is easy to lie with statistics. It is hard to tell the truth without it" A. Dunkels
- English

Biostatistics & Epidemiology
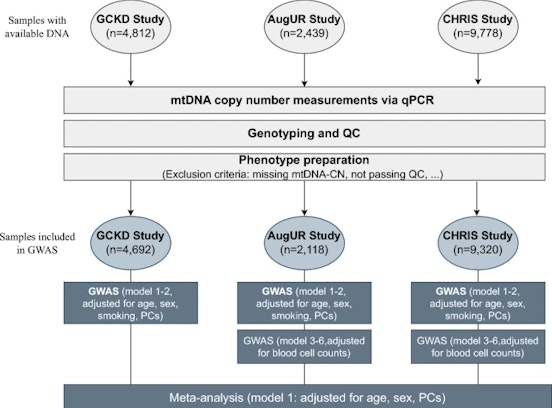
The group conducts cross-disciplinary scientific research in the fields of epidemiology and biomedical statistics, with a strong emphasis on genetic and molecular epidemiology. The group is responsible for the design and planning of population-based and clinical studies conducted by the Institute and the analysis of data from these studies. To conducting genetic association and causal inference studies, the group plays a key role in several international genetic epidemiology consortia. In addition to a conspicuous publication record, the academic background of many senior members favors an educational approach towards junior colleagues, reinforcing the team spirit. The same attitude leads the group to propose frequent educational activities in statistics and epidemiology, aimed at colleagues from other disciplines and different stakeholders in the field of public health.
Biomedical Informatics
We focus on the development and application of computational methods to investigate the molecular basis of disease. More specifically we explore genetic and metabolite signatures and their relation to human health. We also develop and apply approaches to identify families where health related traits tend to aggregate, to help us better understand the environmental and genetic determinants of human health. The work is mostly application oriented, making use of the most appropriate tools for each task. We are also committed to method development, by improving existing tools or developing new ones.

Computational Metabolomics
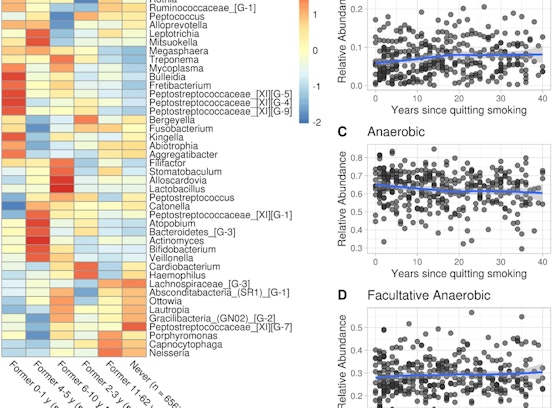
The focus of the computational metabolomics group is on the generation and analysis of mass spectrometry (MS) data sets and the development of software to facilitate their analysis. Making use of the data collected within the CHRIS population study we analyze familiality of metabolite concentrations and aim at identifying relationships between metabolites, environment, lifestyle and diet. We are developing several R packages for the analysis of MS data with an emphasis on large scale data processing and on facilitating annotation and identification in untargeted metabolomics.
Photo: Eurac Research
Computational Genomics
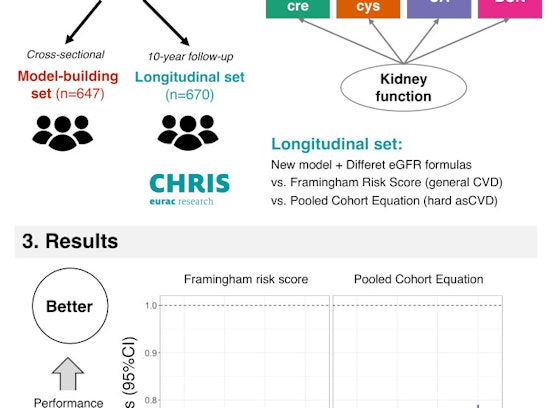
We focus on the development of computational and statistical analysis methods and tools for human genetic studies, and their application to human health and disease. Our gene mapping research encompasses a wide range of complex diseases with a special focus on type 2 diabetes (T2D) and related traits. Our methods work is centered on the development of computational approaches to enable researchers to translate high throughput genomic data into scientific insights. We have developed several popular open source tools, including the GWAtoolbox, minimac, and the Michigan Imputation Server